
Here is an assumption worth challenging: the quality of your experimentation program is determined by what happens after you press “go live.”
It isn’t. It’s determined by what you put in.
Generation got cheap. Selection got expensive. That phrase captures what the past three years of AI have actually done to the digital experience landscape. And it explains why the standard approach to experimentation is showing its limits in ways that weren’t obvious before. When teams could produce one or two polished variants, the bottleneck was creation. Now that teams can produce dozens, the bottleneck has moved. The question is no longer “can we build enough?”, it is “how do we know which one to test?”
Most experimentation teams I talk to are sophisticated. They understand statistical significance. They know how to instrument a funnel, interpret a p-value, and build a testing backlog that maps to business outcomes. They’ve invested in platforms - Optimizely, in many cases - that have turned experimentation from a one-off tactic into the connective tissue of a modern digital experience program. As Gartner defines the category, a Digital Experience Platform is the integrated set of technologies enterprises use to compose, manage, deliver, and continuously optimize connected digital experiences. The operative word here is optimize. Experimentation is how that optimization actually happens.
But here is the gap nobody talks about enough: the quality of what enters the experiment.
The cost of a preventable loss
Consider what a wasted test actually costs. A landing page goes into an A/B test. Traffic splits. You wait two weeks. The challenger loses - not because the hypothesis was wrong, but because users couldn't find the CTA. The design had a visibility problem that a few seconds of attention analysis would have caught before a single real user ever saw it.
Now, calculate what that cost. Two weeks of traffic on a page handling hundreds of thousands of sessions. An analyst’s time building and reading the test. A slot in a testing calendar that has maybe a dozen slots a quarter. And the most expensive line item of all: the wrong conclusion. The team files this away as “that hypothesis didn’t work” when the truth is the hypothesis never got a fair trial. The next idea inherits the same blind spot.
This happens constantly. Not because teams are careless, but because the standard toolkit for evaluating design before it goes live has always been incomplete. Analytics, heatmaps and user testing all tell you what happened. But everything is retrospective. By the time the outcome is measured, every upstream cognitive step (did users see it? understand it? register the message? find the CTA?) has collapsed into a single result. We ship the winner and we still cannot explain why it won.
The most important question: will this design direct attention where the attention needs to go, before a single real user sees it? has historically had no fast, scalable answer. That’s the gap that “pre-launch testing” was built to close.
The AI that experimentation actually needs
There’s a version of “AI in experimentation” that has become almost ubiquitous: a large language model (LLM) generating copy variations, summarizing test results, or suggesting next steps from a backlog. These are genuinely useful capabilities. LLMs are extraordinary at language, reasoning, and synthesis, and the best experimentation platforms are right to integrate them.
But LLMs were not trained to predict human visual perception, They were trained on text. When you ask one whether a user will notice a CTA in the bottom-right corner of a page before they scroll, it cannot tell you because that question requires something different: models trained on biometric ground truth, on years of eye-tracking data collected from real humans interacting with real images and interfaces.

EyeQuant’s predictions are built on more than a decade of neuroscience and eye-tracking research, calibrated against a body of human behavioral data that no recent entrant can replicate quickly. The result is a 90%-confidence prediction of where users will direct their attention first on any given interface. That is not a claim about language or reasoning. It is a claim about human visual behavior, grounded in the scientific data required to make the claim.
These are two different types of AI solving two different problems. That is, a model trained on text cannot reliably assess whether a visual layout will capture attention at the moment it counts.
LLMs can generate, reason, and synthesize. Behavioral models predict, validate, and prioritize. They’re not competing but complementary - each doing what the other cannot.
Compressing the loop
The modern experimentation loop runs something like this: design idea → hypothesis → variant build → QA → test launch → traffic → result → learning. The back half of that loop, from launch to learning, has been compressed significantly by mature experimentation platforms. Optimizely, to its credit, has been at the forefront of that for years.
Design reviews still run long because teams are debating opinions rather than looking at evidence. Variants still enter tests carrying structural weaknesses that traffic has to expose. High-quality hypotheses get delayed because there's no fast way to validate the design behind them before it goes live.
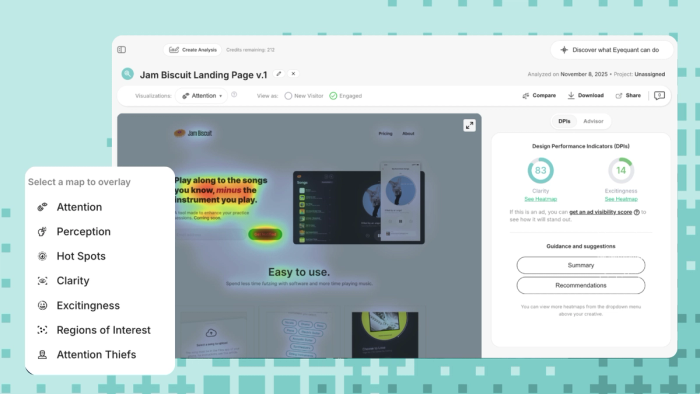
Pre-launch testing changes all that. When you can upload a design and know in seconds where users will look first, whether the primary message registers before they scroll, and whether the CTA is visible, you stop sending your weakest candidates into Optimizely. You start sending your strongest. The experiment becomes confirmation of a well-formed hypothesis, not a discovery of a preventable problem.
What it can’t do, and why that matters
A fair question: if a model can predict where attention goes, does it replace the test?
In short, no - the distinction is the whole point. Predictive attention analysis validates the design: whether the message registers, whether the CTA wins the page, whether attention lands where the hypothesis needs it to. It does not validate the strategy. It won't tell you whether the offer is right, whether the audience is the right one, or whether the underlying hypothesis about user motivation holds. That is exactly what the experiment is for.
Pre-launch attention analysis cleans up the design so your experiment can focus on the only question that matters - does this idea work?
The two aren't in competition. Pre-launch attention analysis cleans up the design so your experiment can focus on the only question that matters - does this idea work?
What AI-assisted experimentation should actually mean
The phrase “AI-assisted experimentation” is being stretched to cover a lot of ground right now. Some of it deserves the label. Some of it is simply a chatbot bolted onto a CMS.
The version worth demanding is one where AI operates across the full loop, not just the back half. Where general-purpose models handle language, personalization, and synthesis. Where specialized behavioral models handle perception, attention, and visual validation, upstream of the experiment, before the traffic is committed.
That is the direction we are building toward at EyeQuant. Specialization. And it is the conversation the experimentation industry needs to be having more openly — about what kinds of AI belong in the stack, what each is actually trained to do, and what it costs when you confuse the two.
Try it on your last losing variant
Don’t take my word for it. Take your last losing variant — the one that should have won — and run it through predictive attention analysis before your next test cycle. If the design had a visibility problem, you’ll see it in seconds. If it didn’t, you’ve lost nothing but a few minutes. Either way, you will know something about your input quality you didn’t know before.
If you’re running an experimentation program and want to see what pre-launch testing could do for your hypothesis quality, start with your last losing variant and try it in EyeQuant, for free.